

Building a RAG Pipeline with pgvector and a Local LLM: A Walkthrough That Actually Works On-Prem
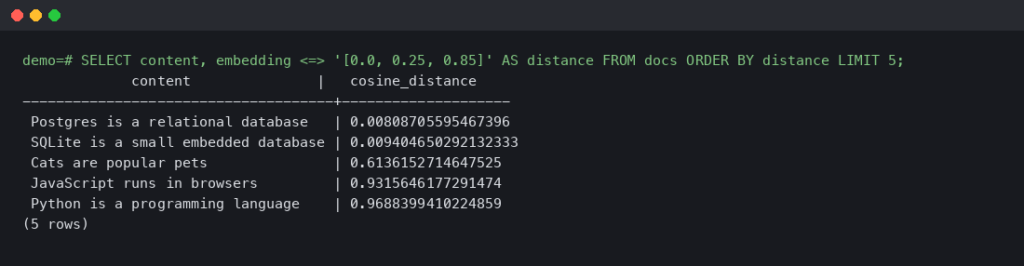
Most RAG (retrieval-augmented generation) tutorials in 2024-2025 assumed you'd ship documents to OpenAI for embeddings, store the vectors in Pinecone or.