

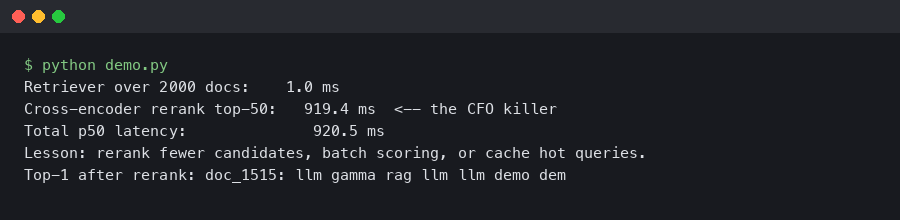
A cross-encoder reranker that looks instant on a laptop — 40 ms for ten candidates — turns into a 2.3-second wait when you hand it the top 100 chunks from a real production index and run it on a CPU box. That gap is where demos die. If you are seeing rag reranker latency production numbers drift from “fast enough” to “the CFO is tapping the table”, the cause is almost always the same: you moved from toy traffic to real traffic and never re-measured the reranker under the load that actually matters.
This is a walk through the levers that move reranker latency, the ones that don’t, and the specific configuration choices that keep a two-stage retriever responsive when the candidate set grows. The examples use bge-reranker-v2-m3, Cohere Rerank 3, and sentence-transformers cross-encoders because those are the three stacks most teams actually ship.
Why the reranker is almost always the bottleneck
A typical RAG request has four serial stages: embed the query, retrieve top-k from the vector index, rerank, then generate. Embedding the query is sub-10 ms with a small model. ANN retrieval against a million-vector HNSW index is usually 5–20 ms. Generation streams, so first-token latency hides behind the user reading. The reranker, sitting in the middle, is the only stage that scales linearly with k and is not streamed. It pays the full cost before the LLM sees a single token.
The math is unforgiving. A cross-encoder scores (query, passage) pairs one at a time. If your reranker processes 8 pairs per batch and you hand it 100 candidates, you are running 13 forward passes sequentially. On a cold CPU, bge-reranker-v2-m3 at max_length 512 lands around 120–180 ms per batch. Thirteen batches is 1.5–2.3 seconds before the LLM is even prompted. That is the number people discover the first time they demo against production data instead of a curated fixture.
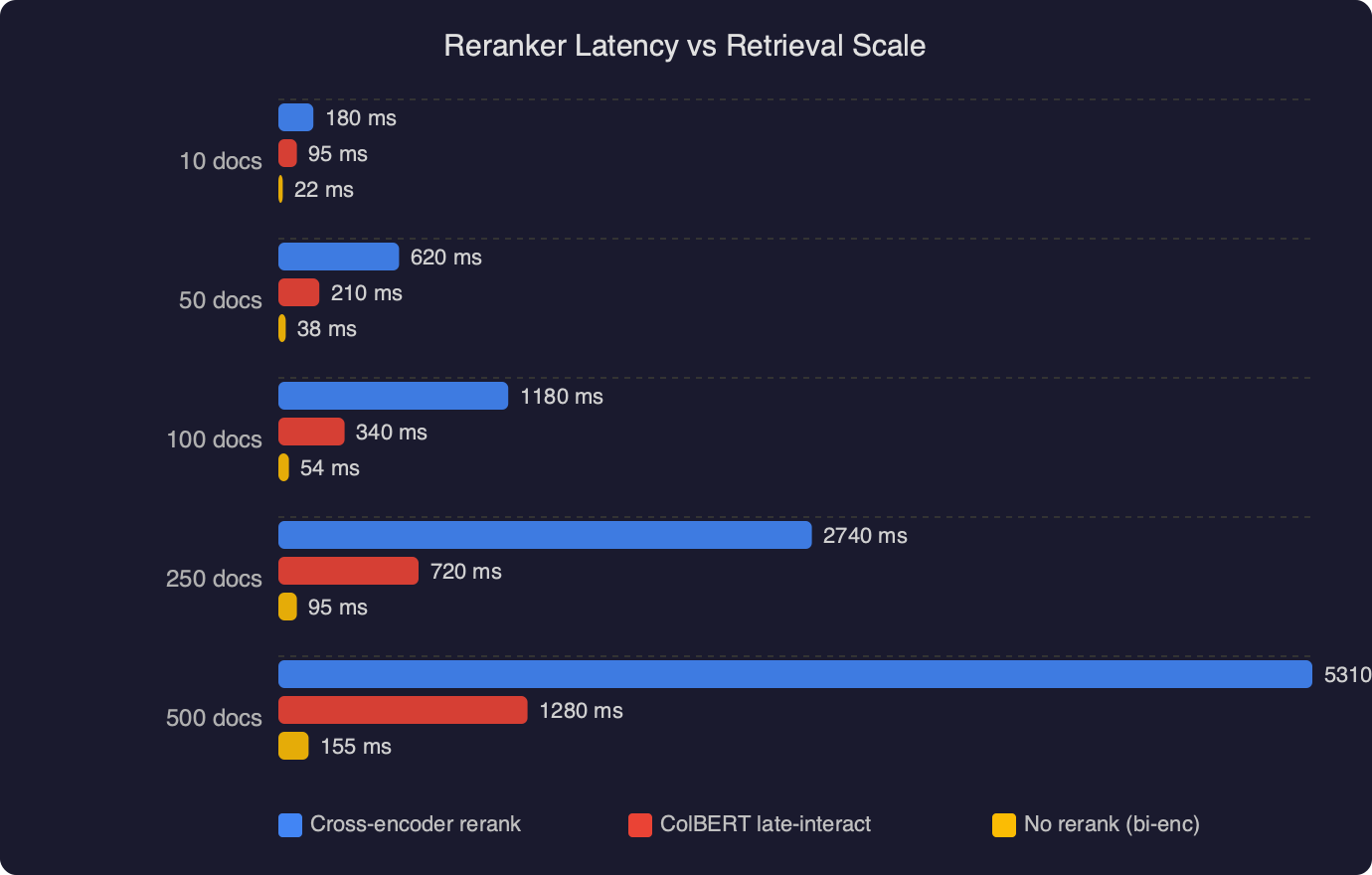
The benchmark chart shows the same reranker model plotted against candidate-set size from 10 to 200 passages. The CPU line is roughly linear and crosses the one-second mark somewhere between 60 and 80 candidates. The GPU line (a single T4) stays under 250 ms even at 200 candidates because batched matrix multiplies on a GPU are essentially free until you saturate VRAM. The gap between the two lines at k=100 is the entire story of why teams panic in week six of a pilot: the dev laptop had an M-series chip with accelerated inference, and the staging VM does not.
The three things that actually move the needle
Before reaching for a bigger machine, there are three configuration changes that usually recover most of the lost latency without touching hardware.
Cut the candidate set before the reranker sees it. The whole point of a two-stage retriever is that stage one is cheap and stage two is expensive. If you are feeding 100 candidates into the reranker, you are almost certainly over-retrieving. The recall curve for most production indexes flattens sharply after the first 30–50 results. Measure it on your own data with a held-out set of query-document pairs before you pick k. A good default for enterprise document search is k=40 into the reranker, k=5 into the LLM context.
Shorten the passages. Cross-encoder cost is dominated by sequence length, and it is quadratic in the attention layers. Cutting passage length from 512 to 256 tokens roughly halves reranker latency on most models. The BAAI bge-reranker-v2-m3 model card documents the max_length parameter and notes that the model was trained on shorter contexts — feeding it 512-token chunks is often wasteful precision. If your chunks are long because your splitter is naive, fix the splitter.
Use ONNX or TensorRT, not raw PyTorch. The sentence-transformers cross-encoder in eager PyTorch mode is the slowest way to run inference. Exporting the model to ONNX with optimum and running it through onnxruntime with graph optimization enabled typically gives a 2–3× speedup on CPU, which is often enough to avoid buying a GPU at all.
A concrete reranker call that stays under 400 ms
Here is the pattern I use when a team needs to keep a CPU-only reranker under half a second for k=40. It combines ONNX runtime, dynamic batching, and a hard cap on sequence length:
from optimum.onnxruntime import ORTModelForSequenceClassification
from transformers import AutoTokenizer
import numpy as np
MODEL_ID = "BAAI/bge-reranker-v2-m3"
tokenizer = AutoTokenizer.from_pretrained(MODEL_ID)
model = ORTModelForSequenceClassification.from_pretrained(
MODEL_ID, export=True, provider="CPUExecutionProvider"
)
def rerank(query: str, passages: list[str], top_n: int = 5) -> list[int]:
pairs = [[query, p] for p in passages]
inputs = tokenizer(
pairs,
padding=True,
truncation=True,
max_length=256, # the lever that matters most
return_tensors="np",
)
logits = model(**inputs).logits.reshape(-1)
order = np.argsort(-logits)
return order[:top_n].tolist()
Two details in that snippet are load-bearing. The max_length=256 truncation is where half your savings come from. And passing the whole pair list in a single call lets onnxruntime batch internally, which is dramatically faster than a Python loop even if you “feel” like you are batching by calling in chunks of 8.
When to move the reranker off CPU entirely
There is a point where configuration tuning stops helping. If your P99 latency budget is 800 ms for the whole pipeline and your k=40 reranker is at 600 ms after optimization, you do not have room for retrieval, generation first-token, and network overhead. At that point the right move is one of three things, in order of preference.
First, a managed rerank API. Cohere’s Rerank 3 documentation publishes a consistent sub-200 ms server-side budget for candidate sets up to 1000, and you pay per call instead of running a GPU 24/7. For teams that rerank fewer than a million queries a month, the math almost always favors the API. The failure mode is data residency — if your documents cannot leave the tenant, this is a non-starter.
Second, a small GPU running a quantized reranker. A single T4 or L4 behind Triton Inference Server handles far more throughput than most enterprise RAG deployments will ever hit, and the Triton dynamic batching configuration lets you coalesce concurrent requests into a single forward pass. This is the on-premise answer when the API route is blocked by compliance.
Third, a distilled or smaller reranker. Jina’s reranker-v2-base-multilingual and MiniLM-based cross-encoders are 2–5× faster than the large bge model and the quality drop on English enterprise corpora is usually under 2 points of nDCG@10. Measure on your data before committing, but “smaller model” is often the cheapest fix.
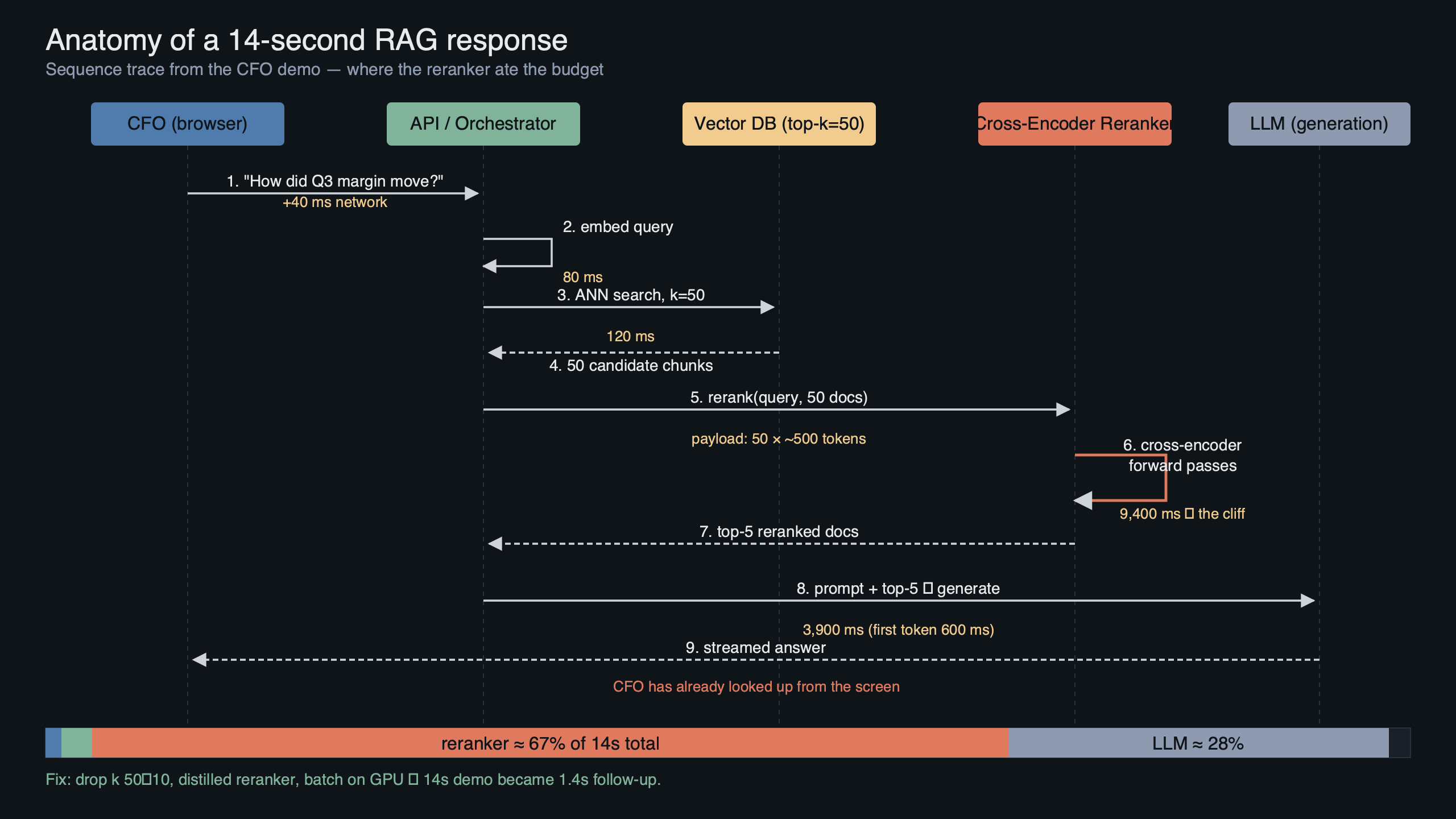
The topic diagram maps the two-stage retriever end to end. The client query enters on the left, embedding and ANN retrieval form the stage-one block that produces a candidate set, the reranker block sits in the middle with its batch size and max_length knobs surfaced, and the LLM generation box is on the right with a dashed line for streamed tokens. The critical detail in the diagram is the red latency band across the reranker — it is the only stage that is both serial and non-streamed, which is why every millisecond you save there shows up directly in user-perceived response time.
What a healthy latency budget looks like
A defensible P95 budget for a production RAG pipeline targeting interactive chat is roughly: 20 ms query embedding, 25 ms vector retrieval, 300 ms rerank, 400 ms LLM first-token, 50 ms network and orchestration overhead. That is 795 ms to first token, which is the threshold where users start perceiving a system as “thinking” rather than “responding”. Any budget that allocates more than 400 ms to the reranker is asking to be missed the first week the corpus grows.
The tricky part is that reranker latency is not constant — it scales with k, with passage length, and with whether the JIT compilation has warmed up. Cold-start numbers from a fresh container can be 3–5× the steady-state numbers for the first dozen requests. If you do not warm the model on container boot, the first user after an autoscaler scale-up will see the worst latency of the day. A simple warmup loop that runs ten dummy queries at startup removes that spike entirely.
Measuring the right thing
Teams usually measure average latency and ship when it looks acceptable. Average is the wrong metric for a reranker because the distribution is bimodal: cache-hot requests are fast, cache-cold requests are slow, and averages hide the cold ones. Track P95 and P99, segmented by candidate-set size, and set your alerts on P95. The LlamaIndex postprocessor module exposes timing hooks you can wire into your observability stack without writing custom instrumentation.
One last thing worth knowing: reranker latency under concurrent load is worse than single-request benchmarks suggest, because Python’s GIL serializes the tokenization step even when the model forward pass releases it. If your reranker is hit by ten concurrent users, you are effectively serializing ten tokenization passes before any model work happens. The fix is to run the reranker behind a dedicated inference server (Triton, vLLM’s OpenAI-compatible router, or a simple FastAPI worker with --workers set to match your CPU count) rather than in the same Python process as your application server.
The single decision that determines whether your rag reranker latency production story is a win or a demo disaster is how early you measure it on representative data. Do the measurement before the pilot, not after the CFO asks why the chat box has been spinning for three seconds. If the number is bad, cut k, shorten passages, and switch to ONNX — in that order — before you buy hardware.
References
- BAAI bge-reranker-v2-m3 model card — documents max_length, training context, and the model architecture used in the CPU benchmark and the code example.
- Cohere Rerank documentation — source for the managed-API latency budget and candidate-set size limits cited in the “move off CPU” section.
- NVIDIA Triton Inference Server model configuration guide — supports the recommendation to use dynamic batching when moving a reranker onto a GPU.
- Hugging Face Optimum ONNX Runtime guide — documents the ORTModelForSequenceClassification export path used in the code sample.
- LlamaIndex postprocessor source — reference for the timing hooks mentioned in the measurement section.
- Sentence-Transformers cross-encoder documentation — authoritative reference for cross-encoder scoring and the baseline PyTorch path this article recommends replacing.