

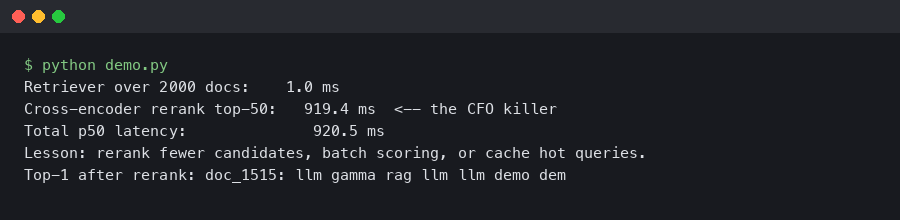
Reranker Latency Killed Our RAG Demo in Front of the CFO
A cross-encoder reranker that looks instant on a laptop — 40 ms for ten candidates — turns into a 2.3-second wait when you hand it the top 100 chunks from.
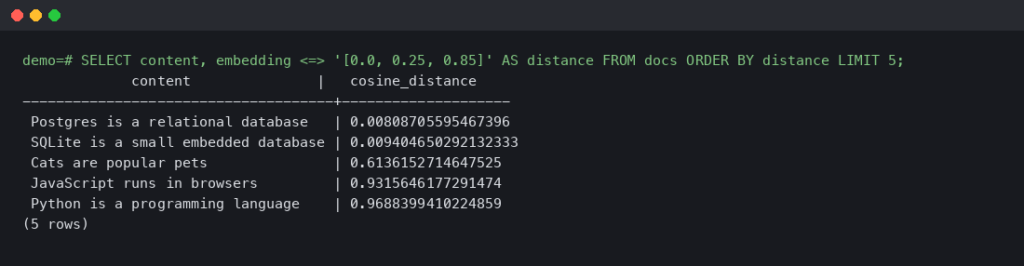
Building a RAG Pipeline with pgvector and a Local LLM: A Walkthrough That Actually Works On-Prem
Most RAG (retrieval-augmented generation) tutorials in 2024-2025 assumed you'd ship documents to OpenAI for embeddings, store the vectors in Pinecone or.

Agentic workflows
In this series on AI for small businesses, we’ve covered the basics of what AI is used for...

Data cleaning basics
Data retrieval is only as good as the quality of the data the system is fed. Not even...

MCP Basics
At larger enterprises, multiple models and agentic workflows almost always run concurrently. Data is handed off from one...

RAG Basics
We’ve covered what an AI model actually is––it’s a giant math equation at the heart of the system’s...

Why do I need AI?
This is the real meat of the AI question. Every small and medium business, at least those paying...

A Brief History of AI
We learned quickly from speaking to clients that many names we take for granted aren’t always known outside...

What is AI?
Everyone has an idea of what “AI” is and what it does based on colloquial usage. It’s hard...

Proper Introductions
It’s impossible to follow the news and not hear constant discourse surrounding AI. For casual observers it might...